Auxiliary Visual Model
The auxiliary visual model automatically enables image support for text-only models by generating detailed visual descriptions of attached images.
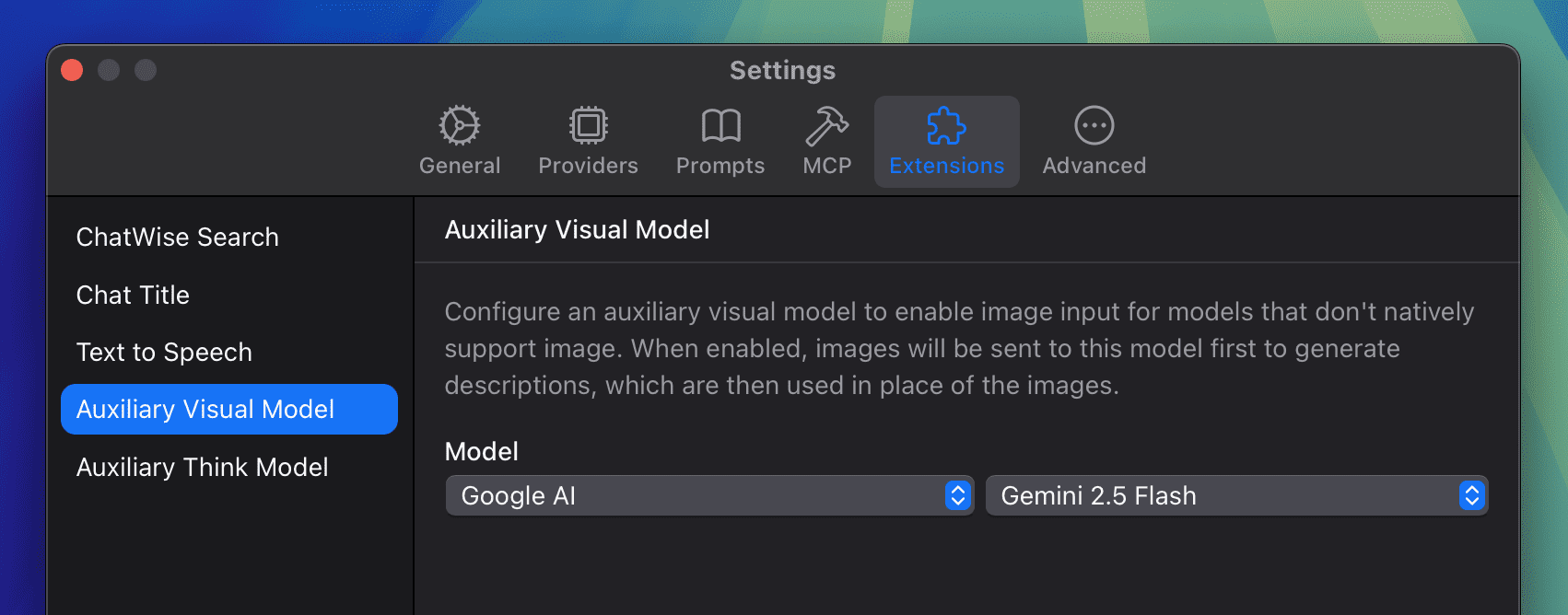
Setting
You can configure an auxiliary visual model in Settings > Extensions > Auxiliary Visual Model. Only models that support image input are available for selection:
How to use?
Simply upload images to your chat as usual. When your current model doesn't support images natively, the auxiliary visual model will automatically process them:
[Upload an image and ask any question about it]
What do you see in this image?How does this work?
When you upload images to a chat:
- Automatic Detection: The system checks if your current model supports image input
- Visual Processing: If not, and an auxiliary visual model is configured, it automatically processes each image to generate detailed descriptions
- Seamless Integration: The visual descriptions are used instead of the raw images when communicating with text-only models
- Caching: Generated descriptions are cached to avoid reprocessing the same images
The auxiliary visual model generates comprehensive descriptions focusing on visual elements, objects, people, text content, scenes, colors, and composition.