@think
You can prepend @think to your prompt to get thought process from DeepSeek Reasonser first and then send the thought process to the current LLM you are using to get an answer based on the thought process.
Which model
By default it automatically detects the official DeepSeek R1 API and the Volcengine DeepSeek R1 API in your settings. (Use Volcengine by default)
If you're using Volcengine, the model name should include r1 (case insensitive) so that it can be identified as DeepSeek R1.
You can also manually select a model that outputs chain of thoughts in a <think> tag in settings:
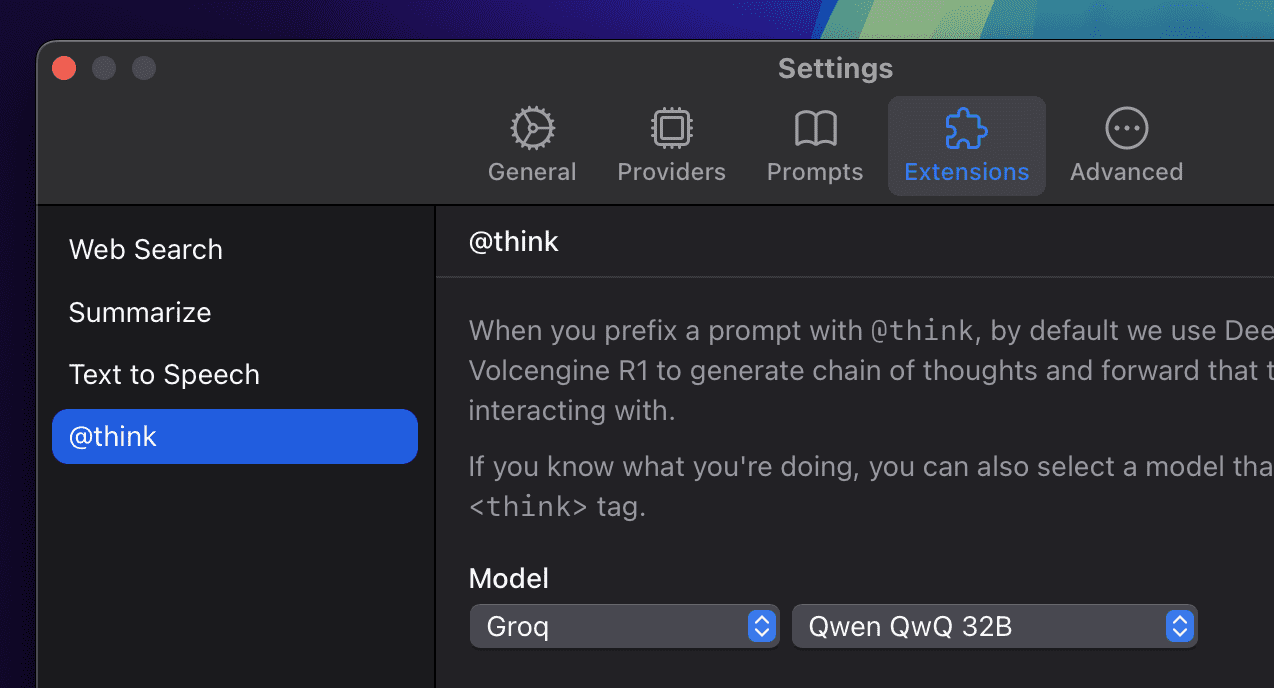
How to use?
@think count r in strawberryHow does this work?
When using DeepSeek Reasoner or Volcengine R1, we limit the max_tokens to 1 to prevent generating the actual answer, as we're only interested in extracting the reasoning process. For manually selected models, we configure a stop sequence of </think> to terminate generation once the thought process is complete.
After obtaining these thoughts, we then prepend this chain of reasoning to your original prompt and send the combined input to your currently selected model to generate the final response.
A supported model must support either:
- Limiting
max_tokensto1and still output reasoning content. - Or
<think>tag so we can use stop sequence to terminate generation.
Models that support max_tokens: 1:
- DeepSeek Reasoner
- Volcengine DeepSeek R1
Providers that support <think> tag:
- Ollama
- LM Studio
- Groq
- Together AI
The followings are tested to not support <think> tag:
- SiliconFlow
- OpenRouter
Others that I'm not aware of, let me know if you have tested other providers.